It was a rough day for the internet. Cloudflare, a global leader in web infrastructure, suffered a massive outage, taking millions of sites and applications—from ChatGPT to X—offline. When the official post-mortem report was released, a seemingly minor technical detail was revealed as the direct trigger for the widespread disruption: a single line of Rust code containing a call to .unwrap().
To a non-Rust developer, .unwrap() might look like an innocuous function. But for Rustaceans, we know its true philosophical meaning: it is the act of escalating a potentially recoverable error into a process-killing panic.
Why would a Cloudflare engineer use this function in such a critical path? Why does the Rust language itself make error handling feel so mandatory and explicit? This global failure provides an unassailable case study to explore the very topic we set out to cover: Why is Rust’s Error Handling Different ?
Introduction
As developers who have been tested by online operations, we are all deeply aware of Murphy’s Law. Any system, if it runs long enough, or if its user base is large enough, will inevitably encounter errors of extremely low probability. For example, a host’s disk might become full, a database system might experience a split-brain scenario, upstream services like CDN might crash, or even the hardware hosting the service itself might fail, and so on.
Because when we write practice code, we usually only focus on the happy path and can ignore the error paths that occur with low probability; but in actual production environments, any error that is not properly handled will plant hidden dangers for the system, ranging from affecting the developer’s user experience to causing security problems for the system, and must not be taken lightly.
In a programming language, control flow is the core process of the language, and error handling is an important part of control flow.
A language’s excellent error handling capability greatly reduces the disruption error handling causes to the overall flow, allowing us to write code more smoothly and with less mental burden when reading it.
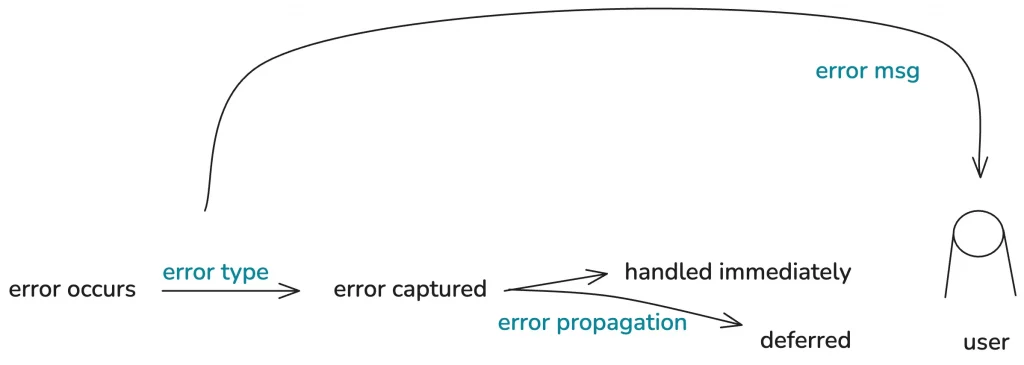
For us developers, error handling includes the following parts:
- when an error occurs, capture it with the appropriate error type.
- After the error is captured, it can be handled immediately, or it can be deferred until it must be handled, which involves error propagation.
- Finally, based on the different error types, provide the user with appropriate error messages that help them understand the problem.
As a programming language that pays great attention to user experience, Rust has absorbed the essence of error handling from other excellent languages, especially Haskell, and presents it in its own unique way.
Mainstream methods of error handling
Before detailing Rust’s error handling methods, let’s slow down a bit and look at the three mainstream methods of error handling and how other languages apply these methods.
Using return values (error codes)
Using return values to represent errors is one of the oldest and most practical methods. Its use is widespread, from function return values, to operating system syscall error codes like errno, process exit codes like retval, and even HTTP API status codes, you can see this method everywhere.
For example, in C language, if fopen(filename) cannot open the file, it returns NULL. The caller checks if the return value is NULL to perform corresponding error handling. Let’s look at another example:
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);Just looking at this interface, it’s hard to intuitively understand how errors are returned when a file read fails. From the documentation, we learn that if the returned size_tdoes not match the passed size_t, then either an error occurred or the end of the file (EOF) was reached. The caller must use ferror to get more detailed error information.
Using return values to carry error information, as in C, has many limitations. The return value has its original semantics. Forcing the error type into the original semantics of the return value requires comprehensive and up-to-date documentation to ensure developers can correctly distinguish between normal returns and error returns.
So Golang extended it, allowing a function to specifically carry an error object upon return. For example, the aforementioned fread could be defined like this in Golang:
func Fread(file *File, b []byte) (n int, err error)Golang, by separating error returns from normal returns, has taken a big step forward compared to C.
However, using the return value method always has a fatal problem: when the caller calls, the error must be handled or explicitly propagated.
If function A calls function B, when A returns an error, it must convert B’s error into A’s error and display it. As shown in the figure below:
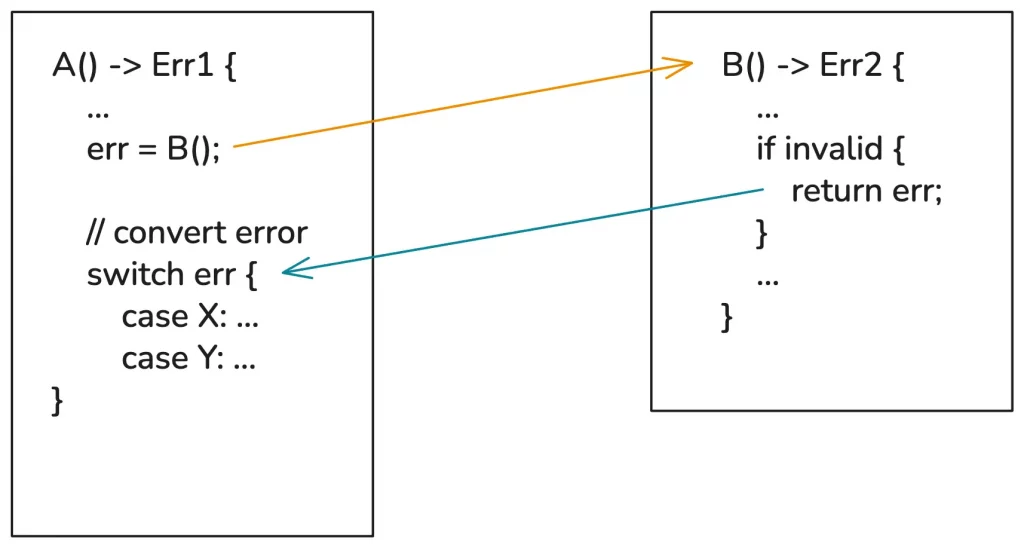
Code written this way can be very verbose, which is not a great user experience for us developers. If not handled, this error information is lost, creating hidden dangers.
Furthermore, most errors in production environments are nested. An error thrown during SQL execution might be a server error, but the deeper error might be an abnormal TLS session state when connecting to the database server.
Actually, besides knowing the server error, we need to understand the underlying cause of the server error more clearly. Because the surface-level server error will be provided to the end user, while the deep-seated cause of the error needs to be provided to us, the service maintainers. However, such nested errors are difficult to perfectly express in C/Golang.
Using exceptions
Because return values are not conducive to error propagation and have many limitations, Java and many other languages use exceptions to handle errors.
You can think of exceptions as a form of Separation of Concerns: the generation of errors and the handling of errors are completely separated. The caller does not need to care about the error, and the callee does not force the caller to care about the error.
Any place in the program that might go wrong can throw an exception; and the exception can be automatically passed layer by layer through stack unwind until it encounters a place that catches the exception. If it unwinds to the main function and no one catches it, the program crashes. As shown in the figure below:
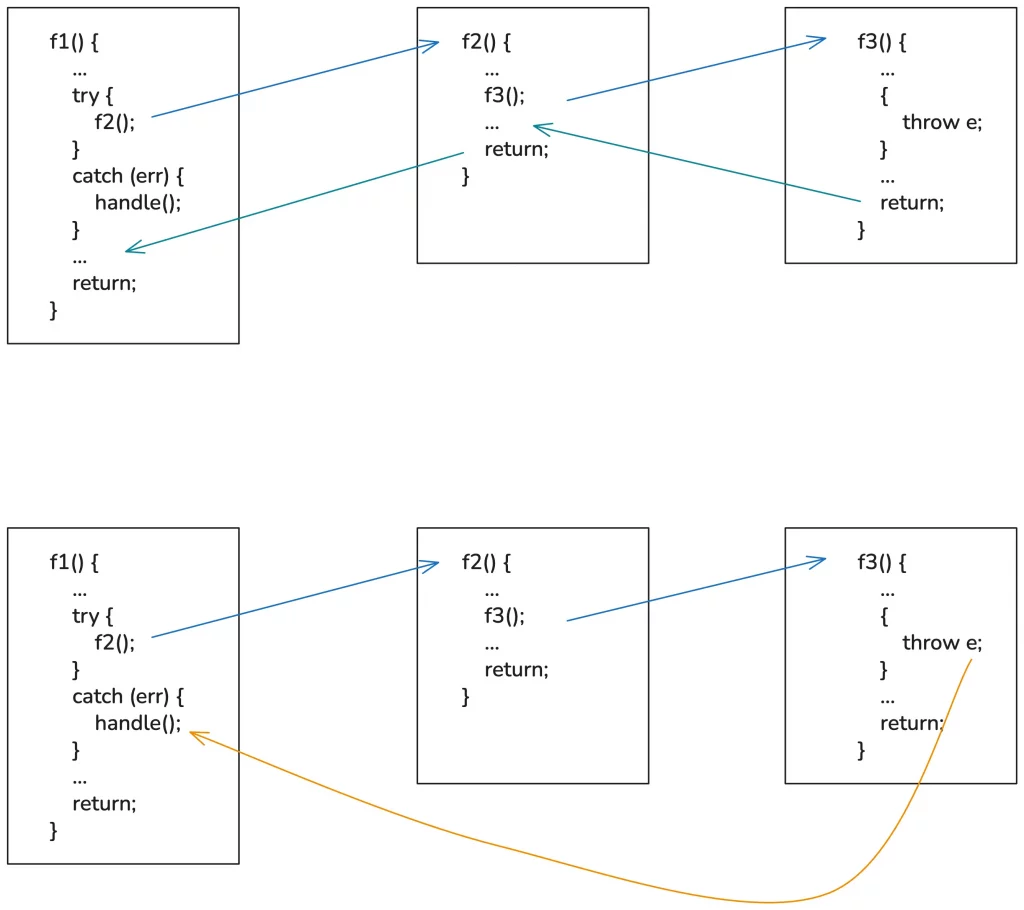
Using exceptions to return errors can greatly simplify the error handling process, as it solves the problem of error value propagation.
However, the process of exception return depicted in the figure above seems straightforward, much like a database transaction being rolled back entirely when an error occurs. But in reality, this process is far more complex than imagined and requires extra attention to exception safety.
Let’s look at the following (pseudo)code used to switch background images:
void transition(...) {
lock(&mutex);
delete background;
++changed;
background = new Background(...);
unlock(&mutex);
}
Consider if creating a new background fails and throws an exception, skipping the subsequent processing steps and unwinding the stack back to the try-catch code. In that case, the locked mutex here cannot be released, the existing background is cleared, the new background isn’t created, and the program enters a strange state.
While using exceptions often makes writing code easier in most cases, when exception safety cannot be guaranteed, the program’s correctness faces significant challenges. Therefore, when using exception handling, you need to pay special attention to exception safety, especially in concurrent environments.
Ironically, the first principle of ensuring exception safety is: avoid throwing exceptions. This is also why Golang, in its language design, avoided conventional exceptions and returned to the old path of using return values.
Another serious problem with exception handling is: developers tend to abuse exceptions. Whenever there’s an error, regardless of its severity or recoverability, they hastily throw an exception. Then, at the necessary point, they simply catch it. They often don’t realize that the overhead of exception handling is much greater than handling return values; abuse leads to a lot of unnecessary overhead.
Using the type system
The third method of error handling is using the type system. Actually, when using return values to handle errors, we already saw the prototype of the type system.
If error information can be carried by existing types or provided through multiple return values, then using a composite type that internally contains both the normal return type and the error return type to characterize errors, and leveraging the type system to enforce error handling and propagation, could achieve better results, right?
Indeed. This approach is widely used in functional programming languages with strong type system support, such as Haskell/Scala/Swift. The most typical composite types containing error types are Haskell’s Maybe and Either types.
The Maybe type allows data to contain a value (Just) or no value (Nothing), which is useful for simple errors that don’t require a specific type. Taking opening a file as an example, if we only care about the successfully opened file handle, then Maybe is sufficient.
When we need more complex error handling, we can use the Either type. It allows data to be either Left a or Right b. Here, ‘a’ is the data type for runtime errors, and ‘b’ can be the data type for success.

We can see that this method still returns errors via return values, but the errors are wrapped in a complete type that must be handled, making it safer than the Golang approach.
As mentioned earlier, a major drawback of using return values to return errors is that errors need to be handled immediately by the caller or explicitly passed on. However, the advantage of using types like Maybe/Either for error handling is that we can use functional programming methods to simplify error handling, such as map, fold, etc., making the code relatively less redundant.
It’s important to note that for many unrecoverable errors, such as “disk full, cannot write,” using exception handling can avoid passing errors layer by layer, making the code concise and efficient. Therefore, most languages that use the type system for error handling will also use exception handling as a supplement.
Rust’s error handling
Having been born later, Rust had the opportunity to learn the pros and cons of error handling from existing languages. For Rust, among the current methods, the best approach is to use the type system to build the main error handling flow.
Rust learned from Haskell, building the Option type, which corresponds to Maybe, and the Result type, which corresponds to Either.

Option and Result
Option is an enum, defined as follows.
pub enum Option<T> {
None,
Some(T),
}
It can carry the simplest error type of having a value / having no value.
Result is a more complex enum, defined as follows:
#[must_use = "this `Result` may be an `Err` variant, which should be handled"]
pub enum Result<T, E> {
Ok(T),
Err(E),
}
When a function fails, it can return Err(E), otherwise Ok(T).
We see that the Result type declaration also has a must_use annotation. The compiler specially handles all types marked with must_use: if the value corresponding to this type is not explicitly used, a warning is issued. This ensures errors are properly handled. As shown in the figure below:

Here, if we call the read_file function and directly discard the return value, due to the #[must_use] annotation, the Rust compiler issues a warning, requiring us to use its return value.
While this can greatly avoid forgetting to handle errors explicitly, if we don’t care about the error and only need to propagate it, we might still write code as redundant as in C or Golang. What to do?
The ? operator
Fortunately, Rust not only has a powerful type system but also possesses metaprogramming capabilities. Early Rust provided the try! macro to simplify explicit error handling. Later, to further improve the user experience, try! evolved into the ? operator.
Therefore, in Rust code, if you only want to propagate errors and not handle them locally, you can use the ? operator, for example:
use std::fs::File;
use std::io::Read;
fn read_file(name: &str) -> Result<String, std::io::Error> {
let mut f = File::open(name)?;
let mut contents = String::new();
f.read_to_string(&mut contents)?;
Ok(contents)
}
Through the ? operator, Rust makes the cost of error propagation comparable to exception handling, while simultaneously avoiding many issues associated with exception handling.
The ? operator is internally expanded into code similar to this:
match result {
Ok(v) => v,
Err(e) => return Err(e.into())
}
Therefore, we can conveniently write code like this, which is concise, easy to understand, and highly readable:
fut
.await?
.process()?
.next()
.await?;
The entire code execution flow is as follows:
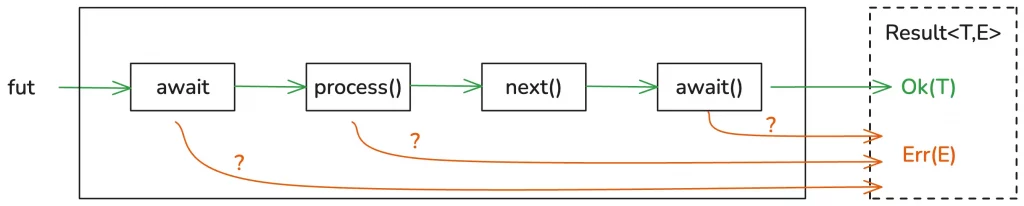
Although the ? operator is very convenient to use, you must note that it cannot be used directly between different error types; it requires implementing the From trait to build a conversion bridge between them, which brings additional trouble. We will temporarily set this issue aside and discuss the solution later.
Functional Error Handling
Rust also provides a large number of helper functions for Option and Result, such as map / map_err / and_then, allowing you to conveniently handle partial cases within data structures. As shown in the figure below:
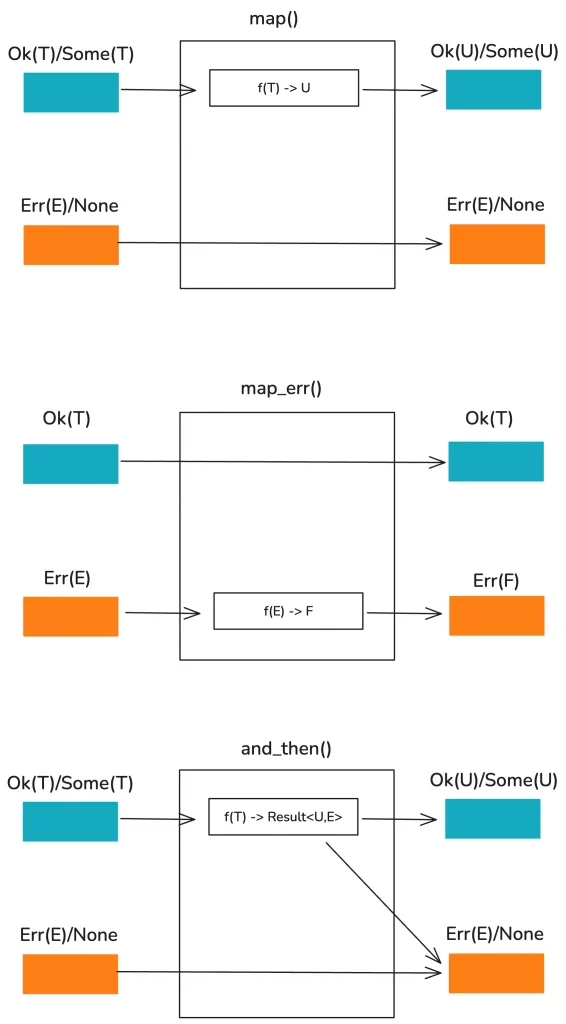
Through these functions, you can easily introduce the Railroad oriented programming paradigm into error handling. For example, in a user registration process, you need to validate user input, process the data, transform it, and then store it in the database. You can write this process as follows:
Ok(data)
.and_then(validate)
.and_then(process)
.map(transform)
.and_then(store)
.map_error(...)
Furthermore, conversion between Option and Result is also very convenient, thanks to the powerful functional programming capabilities built by Rust.
We can see that whether through the ? operator or functional programming for error handling, Rust strives to make error handling flexible and efficient, making it simple and intuitive for developers to use.
panic! and catch_unwind
Using Option and Result is the preferred method for error handling in Rust, and we should use them most of the time. However, Rust also provides special exception handling capabilities.
In Rust’s view, once you need to throw an exception, it must be a serious error. Therefore, like Golang, Rust uses terms like panic! to warn developers: think carefully before using me. When using Option and Result types, developers can also call unwrap() or expect() on them, forcibly converting Option<T> and Result<T, E> into T. If this conversion cannot be completed, it will also panic!.
Generally speaking, panic! is for unrecoverable or errors one does not wish to recover from; we want the program to terminate at this point and provide crash information. For example, the following code parses protocol variables for the noise protocol:
let params: NoiseParams = "Noise_XX_25519_AESGCM_SHA256".parse().unwrap();
If a developer accidentally writes the protocol variable incorrectly, the best approach is to immediately panic!, exposing the error immediately so it can be resolved.
In some scenarios, we also hope to be able to unwind the stack and restore the environment to the context where the exception was caught, similar to exception handling. The Rust standard library provides catch_unwind(), which unwinds the call stack back to the point of catch_unwind, serving the same purpose as try {…} catch {…} in other languages. See the code below:
use std::panic;
fn main() {
let result = panic::catch_unwind(|| {
println!("hello!");
});
assert!(result.is_ok());
let result = panic::catch_unwind(|| {
panic!("oh no!");
});
assert!(result.is_err());
println!("panic captured: {:#?}", result);
}
Of course, as with exception handling, this does not mean you should abuse this feature. I believe this is also why Rust calls throwing an exception panic! and catching an exception catch_unwind, to intimidate beginners and prevent them from using it lightly. This is also a good user experience.
catch_unwind is very useful in certain scenarios, for example, if you are using Rust to write a NIF for the Erlang VM, you do not want any panic! in the Rust code to cause the Erlang VM to crash. Because crashing is a very poor experience, it violates Erlang’s design principle: a process can “let it crash,” but erroneous code should not cause the VM to crash.
At this point, you can encapsulate the entire Rust code within the closure required by the catch_unwind() function. This way, once any code, including code from third-party crates, contains code that could lead to panic!, it will be caught and converted into a Result.
The Error Trait and Error Type Conversion
As mentioned above, in Result<T, E>, E is a data type representing an error. To standardize the behavior of this error-representing data type, Rust defines the Error trait:
pub trait Error: Debug + Display {
fn source(&self) -> Option<&(dyn Error + 'static)> { ... }
fn backtrace(&self) -> Option<&Backtrace> { ... }
fn description(&self) -> &str { ... }
fn cause(&self) -> Option<&dyn Error> { ... }
}
We can define our own data types and then implement the Error trait for them.
However, this work has been simplified for us: we can use thiserror and anyhow to simplify this step. thiserror provides a derive macro to simplify the definition of error types, for example:
use thiserror::Error;
#[derive(Error, Debug)]
#[non_exhaustive]
pub enum DataStoreError {
#[error("data store disconnected")]
Disconnect(#[from] io::Error),
#[error("the data for key `{0}` is not available")]
Redaction(String),
#[error("invalid header (expected {expected:?}, found {found:?})")]
InvalidHeader {
expected: String,
found: String,
},
#[error("unknown data store error")]
Unknown,
}
If you are writing a Rust library, thiserror can effectively help you model all potential errors that might occur in this library.
anyhow implements conversion between anyhow::Error and any error type that conforms to the Error trait, allowing you to use the ? operator without having to manually convert error types. anyhow also allows you to easily throw some temporary errors without the effort of defining error types, although we do not advocate abusing this capability.
As a serious developer, I highly recommend that before development, you use a library like thiserror to define the main error types in your project, and as the project deepens, continuously add new error types, ensuring all potential errors in the system are exposed.
Summary
In this article, we discussed three methods of error handling: using return values, exception handling, and type systems. Building on the shoulders of giants, Rust has drawn from the strengths of various approaches to form the solution we see today: primarily using the type system to handle errors, supplemented by exceptions for unrecoverable errors.
- Compared to C/Golang’s method of handling errors directly with return values, Rust is more complete in its type system, constructing the more logically rigorous
OptionandResulttypes. This avoids errors being inadvertently ignored and also avoids verbose ways of propagating errors. - Compared to the method of using exceptions in C++/Java, Rust distinguishes between recoverable and unrecoverable errors, using
Option/Resultandpanic!/catch_unwindrespectively to deal with them. This is safer and more efficient, avoiding the many problems caused by exception safety. - Compared to its teacher, Haskell, Rust’s error handling is more practical and concise, benefiting from its powerful metaprogramming capabilities and using the
?operator to simplify error propagation.
To summarize: Rust’s error handling is practical, powerful enough, and not overly verbose. It makes full use of the language’s own capabilities, greatly simplifying the code for error propagation. It is clear and concise, almost approaching the ease of exception handling.